背景
临床试验是验证医疗干预措施有效性的关键环节,同时也为患者提供了尝试创新治疗方案的机会。然而,如何高效且准确地将患者与适宜的临床试验相匹配,始终是一项挑战性极大的任务。这一过程不仅涉及分析患者的病历、理解试验的入选标准,还需确保推荐结果兼顾患者需求与试验条件。传统方法主要依靠人工筛选,费时费力,且易受人为因素影响,存在出错风险。
研究契机
人工智能(AI)技术的快速发展,尤其是大语言模型的应用,为提升患者与临床试验的匹配效率和准确性提供了新思路。在患者试验匹配任务中,通常存在两种常见策略:一种是“试验到患者”,即根据特定试验寻找可能符合条件的患者;另一种是“患者到试验”,根据患者情况筛选潜在合适的试验。本研究聚焦后者,以帮助患者及转诊医生快速筛选出符合条件的临床试验。
由阿尔伯特·爱因斯坦医学院、匹兹堡大学、伊利诺伊大学厄巴纳-香槟分校以及马里兰大学帕克分校的研究团队合作,开发了一个基于大语言模型的临床试验患者匹配框架——TrialGPT,旨在以零样本学习的方式实现高效、自动化的患者-试验匹配。
核心挑战
尽管神经网络模型可以通过将患者病历和临床试验标准编码为同一嵌入空间,实现相似度匹配,但在实际应用中仍面临多重挑战:
-
患者记录与临床标准文本语言的差异性与模糊性;
-
缺乏大规模标注的“患者-标准”匹配训练数据;
-
神经网络的黑箱特性,使其难以解释和调试,降低临床医生的信任度。
TrialGPT框架设计
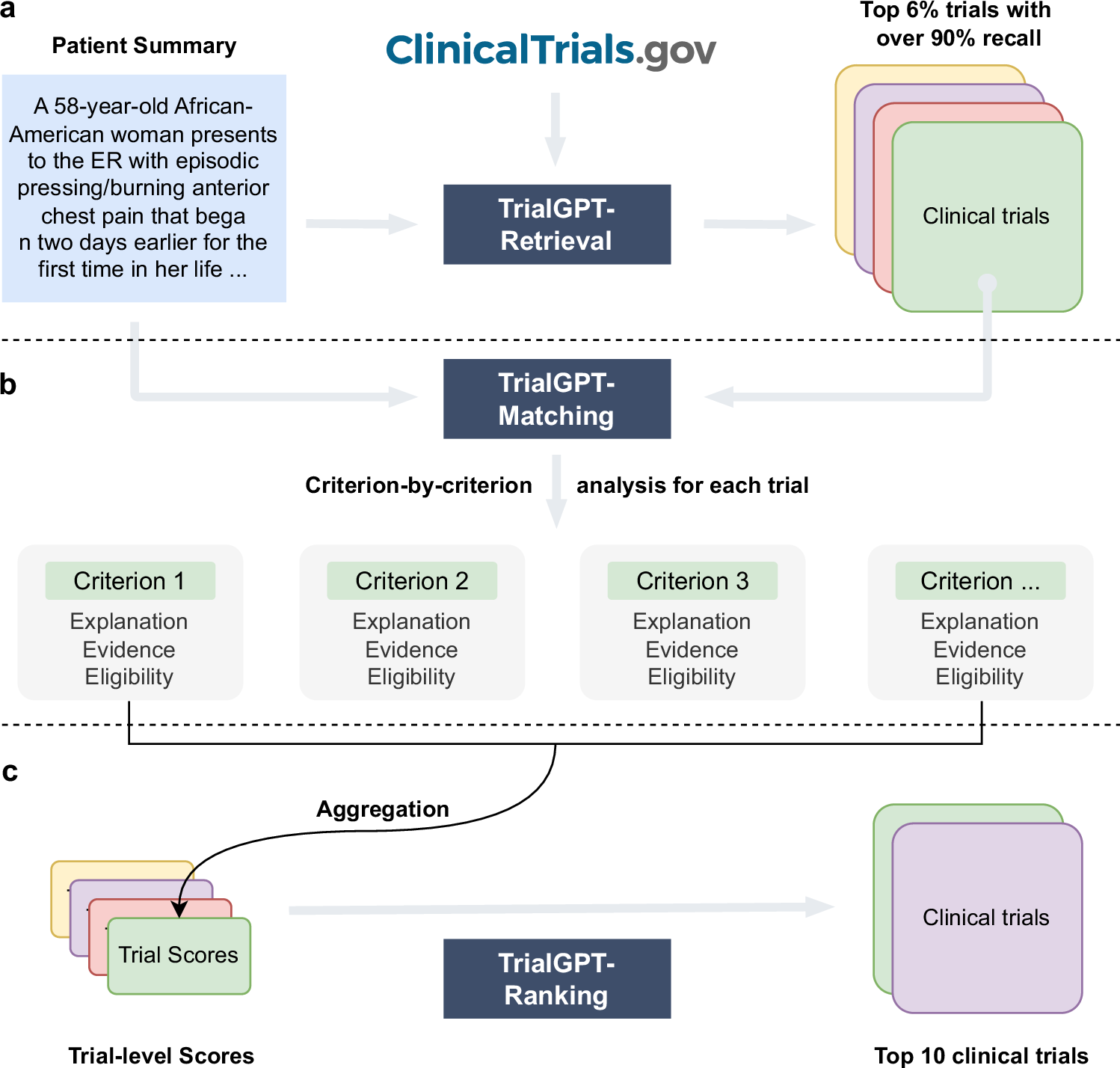
为应对上述问题,研究人员设计了TrialGPT这一端到端解决方案,主要由三个模块组成:
-
TrialGPT-检索
通过大语言模型生成关键词,结合混合检索策略,从海量临床试验数据库中快速筛选出高相关性的候选试验。 -
TrialGPT-匹配
对每个候选试验逐一分析,模型不仅会判断患者是否符合具体标准,还能提供:-
相关性解释;
-
患者病历中支持性证据的句子位置;
-
标准层面的资格分类结果。
-
-
TrialGPT-排序
整合匹配阶段的预测结果,为每个患者生成一个优先级排序列表,最终推荐最有可能符合的临床试验。
性能表现
研究团队基于3个公开数据集,共183名合成患者及超过75,000条试验标准注释,对TrialGPT进行了全面评估。
-
检索阶段,TrialGPT能在不到6%的候选试验中,召回超过90%的相关临床试验,关键词生成效果超越人类临床医生。
-
匹配阶段,在1015对“患者-标准”验证任务中,TrialGPT的解释准确性和资格分类接近临床专家水平,且能准确定位相关证据句子。
-
排序阶段,TrialGPT提供的试验排名结果,与专家注释的相关性高度一致,整体性能比现有基线方法提升43.8%。
实际应用价值
研究还设计了一项模拟真实场景的试点用户研究,针对美国国家癌症研究所(NCI)临床试验平台,比较了使用TrialGPT与不使用时的匹配效率。结果显示,TrialGPT能帮助医学专家在总体上缩短约42.6%的筛选时间,显著提高患者与临床试验的匹配效率。
总结
TrialGPT的提出,为解决临床试验患者招募难题提供了一种创新的人工智能解决方案。其检索、匹配、排序三步法,兼顾了准确性、可解释性和效率,展示出在实际医疗场景中应用的巨大潜力。
Ref.
1.https://www.nature.com/articles/s41467-024-53081-z
2. https://www.nih.gov/news-events/news-releases/nih-developed-ai-algorithm-matches-potential-volunteers-clinical-trials
3. https://github.com/ncbi-nlp/TrialGPT